Overview
Building conversational AI agents is an exercise in iteration. With stochastic systems, confidence is not earned on day one - it is curated over time across two loops. At Quraite, this process is called the Curation Loop: how teams move from:“The agent mostly works” to “We are confident in this agent in production.”
Why the Curation Loop Exists
Most agent teams struggle for two reasons:- Failures are hard to see clearly. Production conversations are noisy, subjective, and difficult to debug.
- Fixes don’t stick. An issue is patched once, but nothing prevents the same failure from returning later.
- Making failures explicit and reviewable
- Converting real failures into replayable test cases
- Continuously growing a living test suite that defines agent quality
Two Loops, One Goal
The Curation Loop consists of two connected loops:- Inner Loop (Development): fast iteration before shipping
- Outer Loop (Production): learning from real user conversations
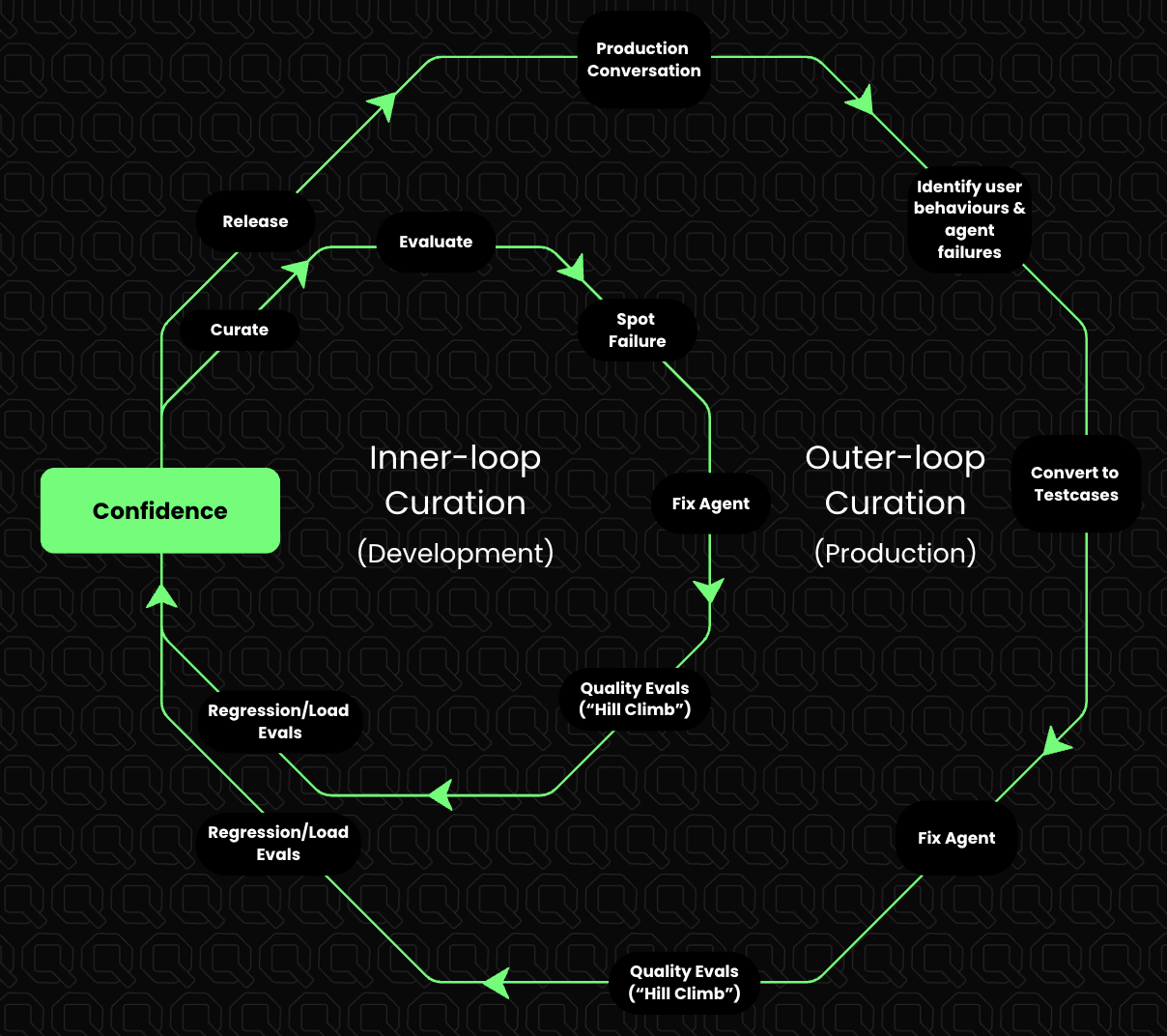
Inner Loop: Curation During Development
The inner loop runs while the agent is actively being built or refined. Models are configured, prompts are crafted, tools are designed, and nothing works perfectly the first time.1. Start With Vibe Evaluation
Before metrics and dashboards, talk to the agent. Run a handful of representative conversations and ask:- Does the response feel helpful?
- Is the tone appropriate?
- Is the agent reasoning correctly?
2. Spot a Failure
As soon as something feels off (e.g., an incorrect answer, hallucination, poor reasoning, bad tone, or refusal), stop and capture it. Do not rely on memory or screenshots.3. Save It as a Test Case
Convert that failure into a structured test case:- Input conversation/scenario
- Expected agent behavior
4. Fix the Agent
Make the change: prompt updates, tool usage fixes, guardrails, retrieval changes, or logic updates. The fix itself is not the goal: verifying it is.5. Replay Against the Test Suite
Replay the saved test case and the rest of the test suite. If the fix works and does not break existing behavior, the improvement is real. This completes one inner-loop cycle.Outer Loop: Curation From Production
Once the agent is live, the most valuable failures come from real users. User research gives hypotheses. Production gives reality.1. Observe Production Conversations
Monitor real conversations for unexpected user behavior, edge cases that weren’t anticipated, and subtle failures that never appear in synthetic tests: agents hallucinating on edge cases, looping endlessly on certain inputs, or mishandling scenarios that were never designed for.2. Surface a Failure
When a production conversation goes wrong, flag it, review it, and decide if it represents a real gap in behavior. Not every odd conversation becomes a test case; only meaningful failures do. These aren’t failures to be embarrassed by. They are signals. Each one indicates what to build next.3. Convert It Into a Test Case
This is the bridge between production and development. A real user failure is transformed into a formal test case and added to the test suite. From this point on, the agent is not allowed to fail this way again.4. Fix and Replay
Fix the agent and replay the entire test suite, including old development cases and newly added production cases. This ensures progress without regressions.The Test Suite Is the Source of Truth
Over time, the test suite becomes:- A record of every important failure observed
- A definition of what good agent behavior looks like
- A safety net for future changes
Confidence Is the Output
The output of the Curation Loops (inner and outer) is not accuracy scores or dashboards. It is confidence: confidence to ship, to iterate, and to trust that fixes won’t regress silently. The teams that win are not the ones who build the best v1. They are the ones who curate confidence fastest across both loops.“Treat your agent like an untrusted worker. Curate your confidence, don’t assume it.”
Key Takeaways
- Start small and early.
- Treat every meaningful failure as an asset.
- Convert production failures into permanent tests.
- Let the test suite grow with the agent.
- Confidence is not assumed; it is curated.